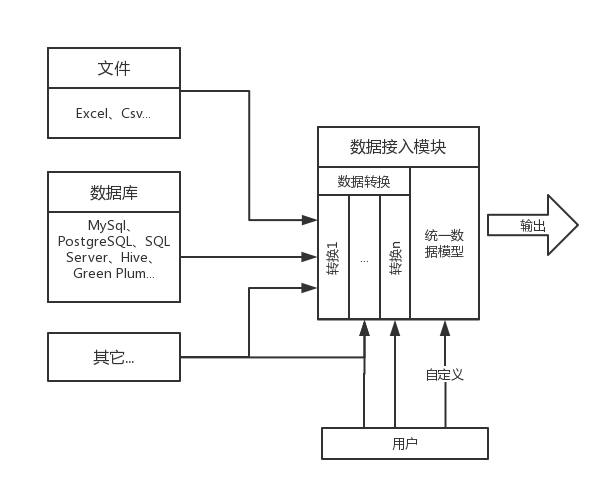
在国产化工作的过程中,技术路线选择的重要性不言而喻。当国产芯片采用不同技术路线发展时,适配迁移也成为关键环节。但往往很多人会认为:我的应用和软件只要与OS适配过,就不用再和CPU进行适配;或者我有全部源代码,只要扔给编译器编译就可以在任何CPU上运行;抑或是有兼容的API就可以忽视所有的CPU。
如果上述为真,那么世界上只要有一种操作系统就可以了,编译一下,所有的平台都能适用。但很可惜,实际情况远比这复杂。
首先,尽管应用程序需要适配不同的操作系统以确保其正确运行和展示,但操作系统的适配并不完全等同于CPU的适配。操作系统是计算机系统的一个关键组成,它管理着计算机的软硬件资源,并为应用程序提供了运行环境。而CPU则是计算机的核心处理器,负责执行程序中的指令。每个CPU都有其独特的指令集和性能特点,应用程序需要针对这些特点进行相应的优化和适配,以确保其能够充分利用CPU性能并正确执行。
 排名链接")
其次,即使拥有应用程序的全部源代码,也并不意味着它可以在任何CPU上编译和运行。编译器只是将源代码转换成特定CPU可以理解的机器代码,但不同的CPU有不同的指令集和架构,因此编译器需要针对特定的CPU进行配置和优化。此外,某些高级特性或优化可能只在特定的CPU或指令集上可用,因此开发者需要针对目标平台进行相应的开发和测试。
更进一步来看,即使有兼容的API,也不能完全忽视CPU的适配问题。API提供了应用程序与操作系统或其他软件组件之间的接口,但它并不涉及到底层的硬件适配。即使API是兼容的,如果应用程序没有针对目标CPU进行优化,那么其性能可能会受到影响,甚至可能出现运行错误或崩溃的情况。
因此,适配操作系统、编译源代码以及使用兼容的API只是软件开发过程中的一环,并非全部。为了确保应用程序能够在不同的平台上正常运行并发挥最佳性能,开发者还需要针对目标CPU进行深入的适配和优化工作。这包括了解目标CPU的指令集、性能特点以及可能的限制,并针对这些特点进行相应的代码优化和测试。
软件迁移的本质
是 “指令集”对源代码的再翻译
所以软件迁移的本质到底是什么?这要先从编程说起。
「TIOBE 编程社区指数」是一种衡量编程语言流行度的标准,由成立于 2000 年 10 月位于荷兰埃因霍温的 TIOBE Software BV 创建和维护。 该指数是根据网络搜索引擎对含有该语言名称的查询结果的数量计算出来的。该指数涵盖了 Google、百度、维基百科和 YouTube 的搜索结果。从https://hellogithub.com/report/tiobe/获悉编程语言的使用排名。
对于编译型语言如C、C++、C#、VB以及Assembly等,在异构平台(即不同硬件架构或操作系统的平台)上进行迁移时,通常需要对代码进行重新检查、修改和调试。因为不同的平台有不同的指令集、内存模型、系统调用和API,以及可能存在的其他差异。这些差异要求开发者对代码进行相应的调整,以确保其能够在目标平台上正确运行。
这个过程往往是反复和繁琐的,因为开发者需要不断地在目标平台上编译和运行代码,观察其行为是否符合预期,并根据出现的错误或异常进行相应的修改。此外,由于不同平台之间的差异可能涉及到底层的硬件细节,因此开发者需要具备深厚的系统编程和硬件知识,以便能够准确地识别和解决问题。
对于解释型语言如Java和Python,虽然它们在一定程度上提供了跨平台的便利,但在异构迁移过程中,版本和编译器/解释器的兼容性仍然是需要关注的重要因素。因为解释型语言依赖于特定的解释器或运行时环境来执行代码,这些解释器或运行时环境可能有不同的版本,每个版本可能具有不同的特性、性能以及可能存在的缺陷。
因此,当进行异构迁移时,确保目标平台上的解释器或运行时环境版本与源代码所依赖的版本兼容是至关重要的。另外,即使解释型语言本身具有一定的跨平台性,但某些特定的库或框架可能并不完全兼容所有平台或版本。这些库或框架可能使用了特定于平台的API或特性,或者可能依赖于特定版本的解释器或运行时环境。因此,在进行异构迁移时,需要仔细检查和测试所使用的库和框架,是否与目标平台上的解释器或运行时环境兼容。
虽然Java和Python等解释型语言通常具有较为统一的语法和语义,但不同的编译器或解释器实现可能在性能优化、错误处理以及内存管理等方面存在差异。这些差异可能会导致代码在不同平台上的行为不一致,因此需要进行充分的测试和验证。
在众多的国内技术路线中,以x86为代表的指令集架构生态兼容最为广泛。在服务器领域,一些厂商凭借丰富的指令、广泛的生态结构和深度的生态体系,几乎可以实现“零成本”迁移。另外,国内也有一些独具特色的技术路线,逐渐形成专属领域的生态结构,伴随着生态规模的发展,未来有望进一步提升兼容能力,降低迁移成本。
但不管怎么说,适配迁移是一个不可或缺的环节,我们需要通过制定详细的计划和方案、选择合适的迁移工具和方法,以及进行充分的测试和验证,以确保迁移的顺利进行并达到预期的目标:
制定详细的迁移计划和方案,明确迁移的目标、步骤和时间表。 对原有的系统或技术进行全面评估,确定需要迁移的模块和功能。选择合适的迁移工具和方法,以提高迁移的效率和准确性。在迁移过程中进行充分的测试和验证,确保数据的完整性和系统的稳定性。制定应急预案,以应对可能出现的风险和问题。最后再回到开篇的问题:往往很多人认为我的应用、我的软件只要和OS适配过,就不用再和CPU进行适配。
大家都知道,在计算机的世界里,也就是现代的计算机都是用 0 和 1 组成的二进制,来表示所有的信息。而软件的设计是属于编程语言的行为产物,软件相当于你所写的文章。同一份文章,在面向不同国家民众阅读的时候,要相应的修改成能够识别的语言。这里不同的国家指代不同的CPU,CPU所能执行指令集代表这个国家所能够识别的语言。
比方说英语,可以说英语跨了所有“平台(国家)”。但是,我们看到英语一个单词的cat,马上会在你的大脑进行神经网络计算,中国人识别cat对应汉语中的“猫”;日本人识别cat对应日语中的“ねこ”。也就是不同的国家,都会对英语进行再翻译。我们之所以能够快速识别,就是因为在前期我们已经对英文知识打基础、做练习,进而我们可以快速翻译英文,并且知道对方说的什么、执行什么。
再来举个例子,比如cat相当于java编写的软件,英语就是JDK,但是不同的国家对英语,或者说对这个JDK编写的教材是不同的,语法也不一样,不同的教材就对应不了不同版本的JDK平台。所以,软件迁移的本质就是“指令集”对源代码的再翻译。