文章目录
[+]
1. 数据收集:首先,需要收集相关的数据,包括已发布的文章、摘要、相关的统计数据等。这些数据可以来自于网站、数据库或其他来源。
2. 数据预处理:对收集到的数据进行预处理,包括文本清洗、分词、去除停用词等。这一步骤旨在准备数据以供后续处理使用。
3. 文本生成模型训练:使用生成模型,如循环神经网络(RNN)或Transformer,对预处理后的数据进行训练。可以使用已有的文本生成模型,如语言模型(如GPT)或生成对抗网络(GAN),也可以根据需求自定义模型架构。
 排名链接")
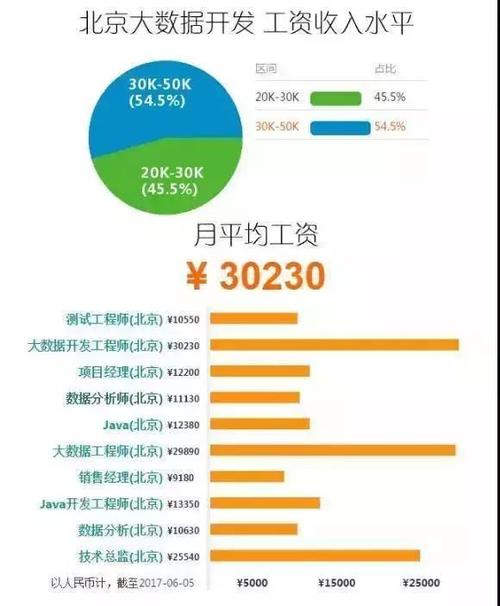
(图片来自网络侵删)
4. 模型微调:对已训练的文本生成模型进行微调,以使其更好地适应生成的任务。可以使用有监督学习的方法,提供人工生成的样本作为训练数据,或者使用强化学习的方法,通过与人工编辑进行交互来优化生成质量。
5. 文本生成:使用训练好的模型生成文本。可以根据需要设定生成的类别、主题、长度等参数,并生成相应的内容。
6. 后处理和编辑:生成的文本可能需要进行后处理和编辑,以确保语法正确、逻辑清晰,并符合写作的规范和要求。可以借助自然语言处理技术进行自动的后处理,也可以人工编辑和审校生成的文本。
需要注意的是,自动化生成的过程中,保持信息准确性和可信度非常重要。在实际应用中,还需要考虑法律、伦理以及行业的规范和道德准则。